Nodes
General graph terminology - nodes & edges
Each 'thing' described in a graph is represented by a node
Two nodes are connected with an edge. In linked data an edge is always 'directed'. That means it points from one node to another. We could say that any node is described by its edges (the properties like "name" or "type") that connect it to other nodes.
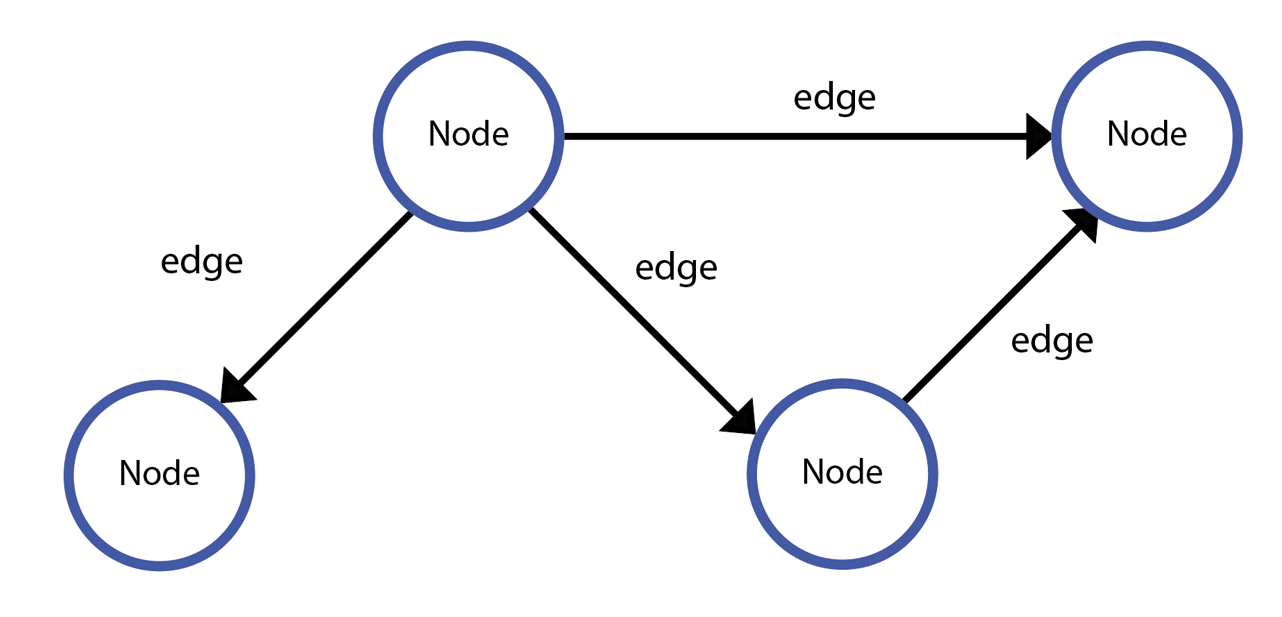
Edges are also nodes
An important thing to note is that in linked data, edges are themselves also nodes in the graph with their own properties.
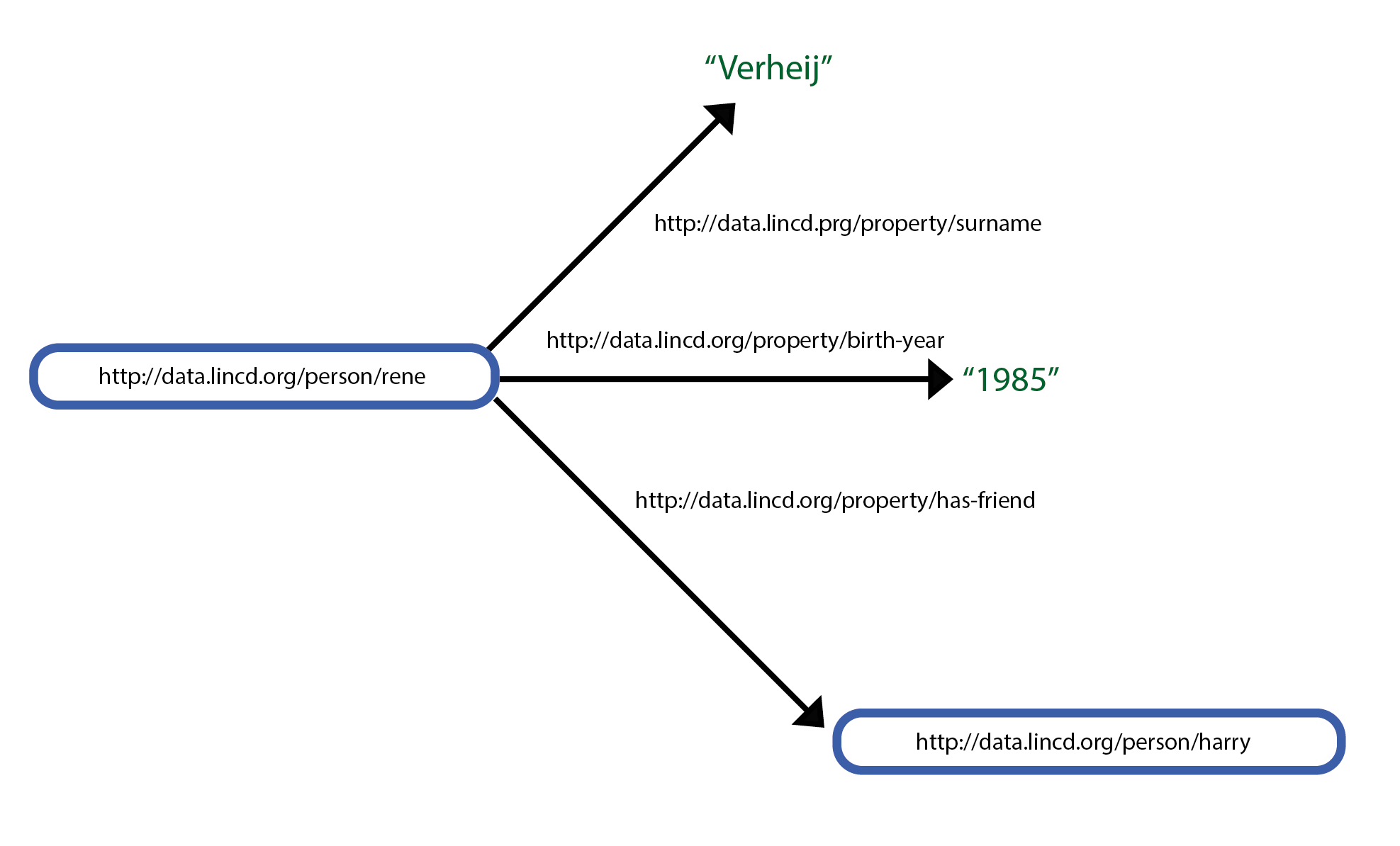
For example, take this graph:
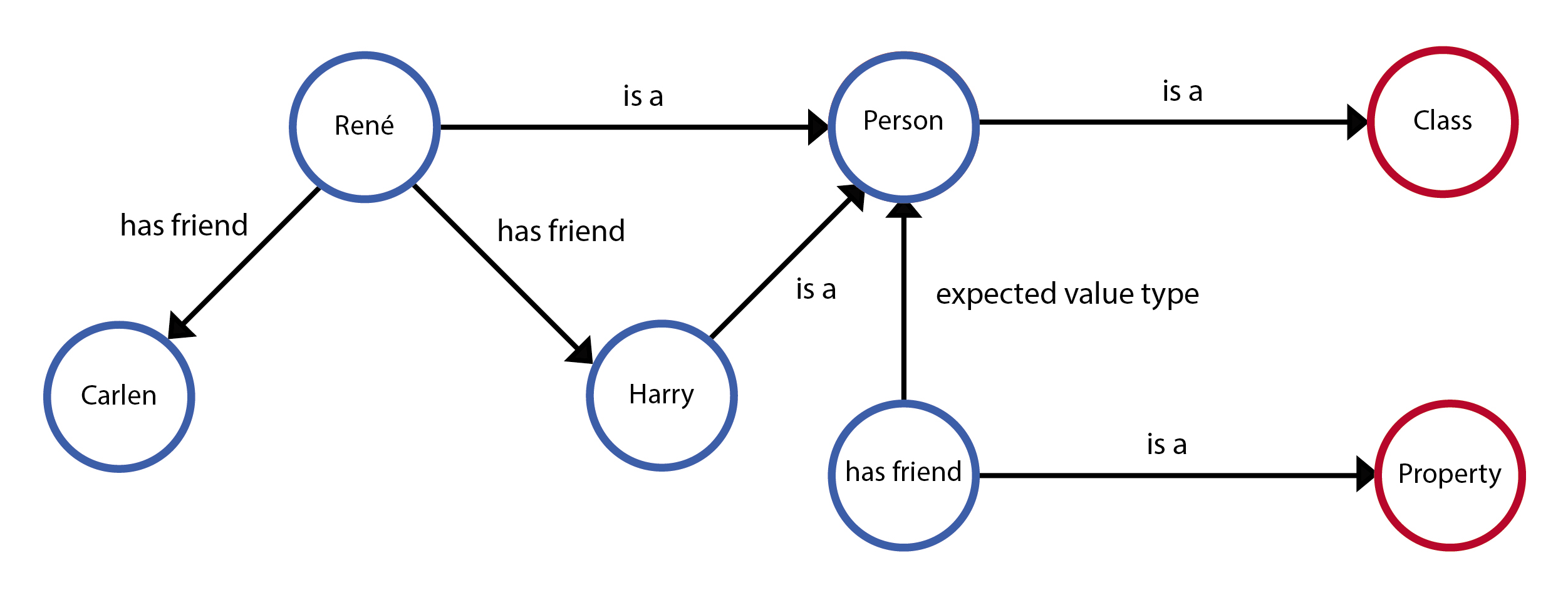
Here you see that has friend occurs as an edge in Rene has friend Harry and Rene has friend Carlen. But has friend is also as the subject node in the statement has friend is a Property
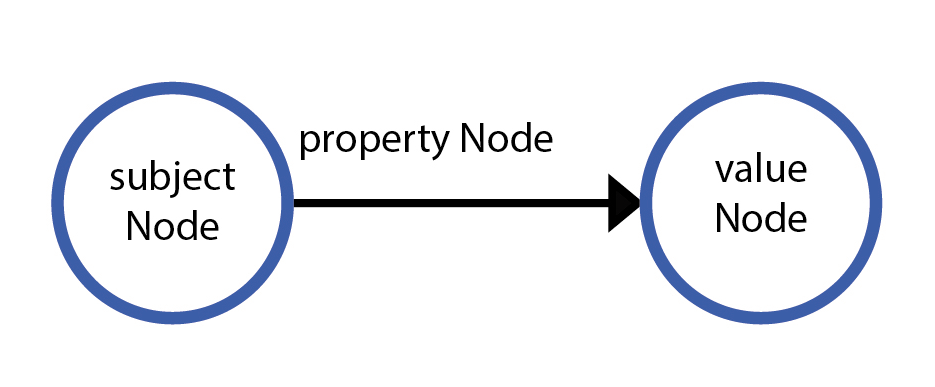
So a triple therefor consists of 3 nodes: A subject node, a property node (officially called the 'predicate') and a value node (officially called the 'object')
Now, in linked data (or RDF, the official standard that defines triples) there are three types of nodes: Named Nodes, Literals and Blank Nodes.
Let's see what they each are:
Literals
Literals are like strings. And unlike the other types of nodes, literals do not have any properties of their own. That is, they never occur as the subject of a triple. Nor can they be properties. They can only occur as the value (or object) of a triple.
You can think of them as 'leaf nodes'.
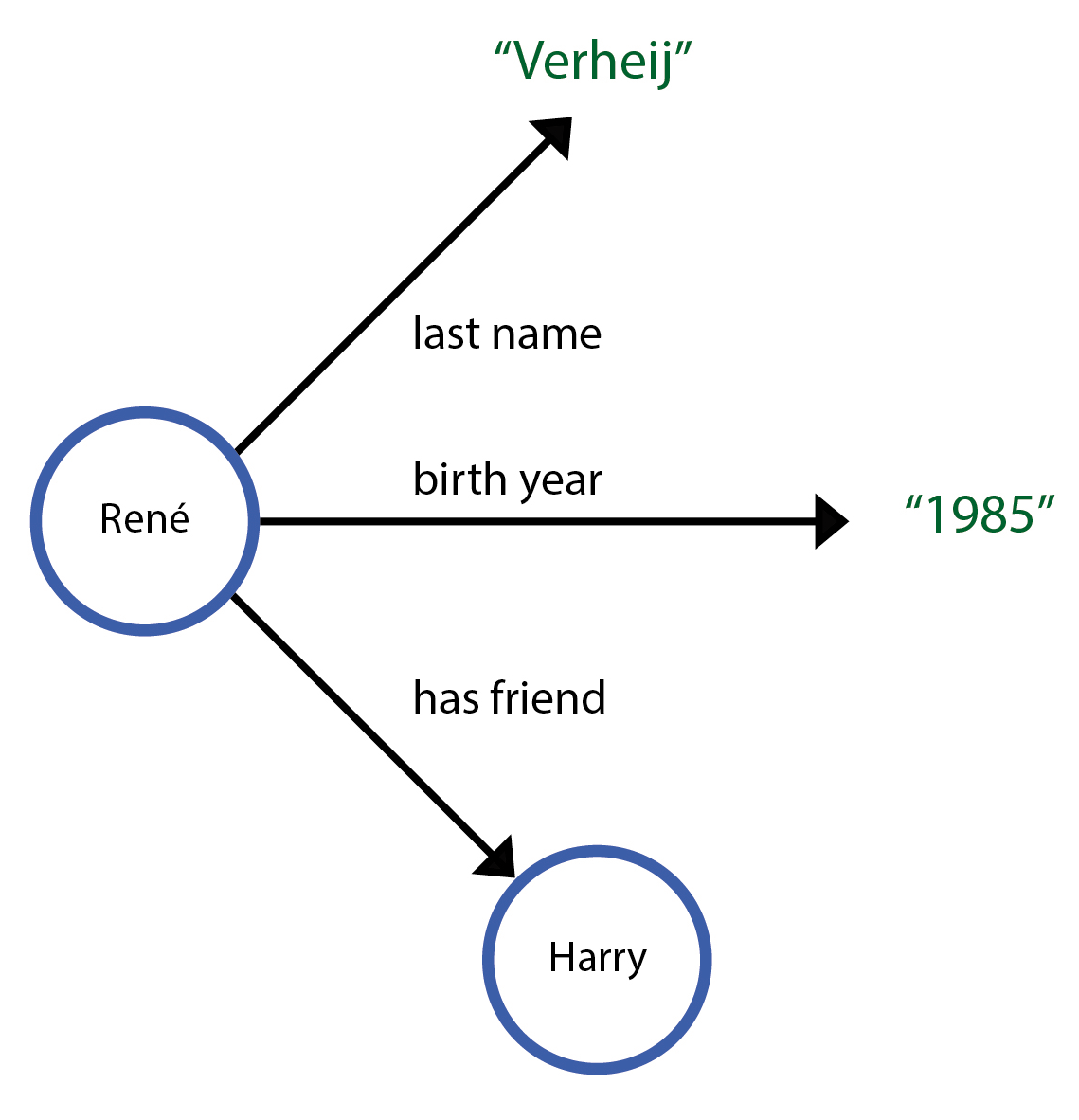
Here, for the 'last name' and 'birth year' properties, the value is a literal. "Verheij" and "1985" cannot have any properties of their own.
Literals can have a datatype, which denotes them as a number, float, date, boolean etc. They can also have a language tag (english, french, chinese, etc). But they can only have one of these.
For now, we won't go into the details of that. If you want to find more information about literals, see their RDF specification
Named Nodes
Named nodes are called 'named' because they are identified by a URI (Universal Resource Identifier).
A URI is almost the same as a URL, but instead of just being http(s), it can include any protocol like ftp://,ssh://, etc.
This URI is unique and can be used in any graph to point to the same thing.
Named can have properties and values. That is, they can occur as the subject in a triple. The thing that the node represents is described by their relation to other nodes. (their properties and values)
All the colored circles in the images above are named nodes. And as said before, the edges (properties) are also named nodes that have their own properties.
So actually, the previous image in looks something like this in reality:
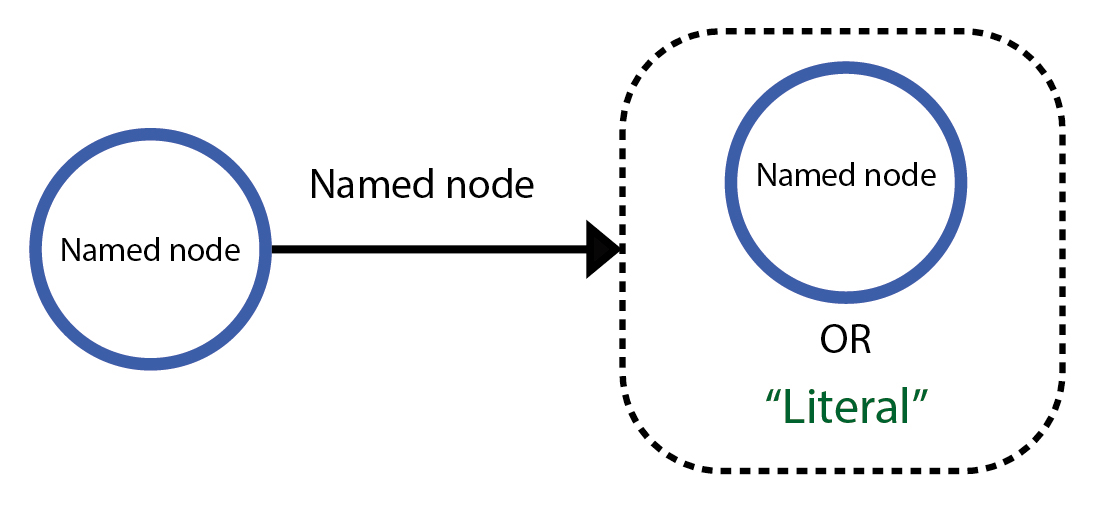
Literal or named node?
When in doubt, just remember only the value of a property can either be a named node or a literal:
Blank nodes
Blank nodes are just like named nodes, except that they don't have a unique URI that can be reused. That is, blank nodes can only be the value of one triple. They cannot be reused in the same graph, or any other graph.
They were invented exactly for this purpose. Because you may sometimes want to use nodes without giving them a URI, and without the possibility of any properties being added to that node later on.
They can also be used when you don't know the proper URI of a node. Perhaps I want to store that I had a meeting with someone, but I just remember the person's name. I can use a blank node for this person, and still add properties to him/her. Knowing they may have a proper URI elsewhere.
Because they don't have a permanent unique URI, blank nodes are often assigned a temporary URI that is only relevant to the current context.
These URI's often look like this: _:01 or _:b1.
But its precisely because blank nodes don't have a URI, that they are also hard to work with sometimes. Therefor:
We recommend you to use named nodes wherever you can, unless you a certain you really need a blank node for your use case.